
OpenAI lanza modelos gpt‑oss que pueden funcionar en móviles de 16 GB, incluyendo el gpt‑oss‑20b, lo que permite ejecutar IA avanzada en smartphones con memorias altas como las de gama alta.

¿Qué modelos presentó OpenAI?
En julio de 2025, OpenAI liberó dos modelos open source: el gpt‑oss‑20b y el gpt‑oss‑120b. Ambos son modelos MoE (experto mixto), basados en la arquitectura Transformer, pero con requisitos diferentes. El primero puede ejecutarse en dispositivos con 16 GB de RAM, mientras que el segundo necesita entornos con hasta 80 GB.
Ejecución en móviles: una posibilidad real
El modelo más ligero, gpt‑oss‑20b, solo requiere unos 10 GB en formato MXFP4, por lo que teléfonos con 16 GB pueden ejecutarlo. Qualcomm ya confirmó que sus chips Snapdragon de gama alta lo soportan. El mismo caso se anticipa para los SoC Dimensity de MediaTek .
Una prueba con un móvil Galaxy S25 Ultra (12 GB de RAM) mostró que incluso al cerrar apps, solo quedaban unos 5 GB disponibles. Por eso, 12 GB resulta insuficiente para estos modelos MoE .
¿Por qué importa esto ahora?
Este avance tecnológico podría cambiar la tendencia en la industria móvil. Muchos fabricantes aún lanzan modelos con 12 GB como estándar. Pero el uso de modelos como gpt‑oss‑20b exige móviles con 16 GB de RAM para garantizar ejecución fluida.
Google Pixel ya ofrece configuración uniforme de 16 GB en su línea Pro. Mientras tanto, muchos iPhones siguen en 8 GB, lo que limita su capacidad para ejecutar estos modelos .
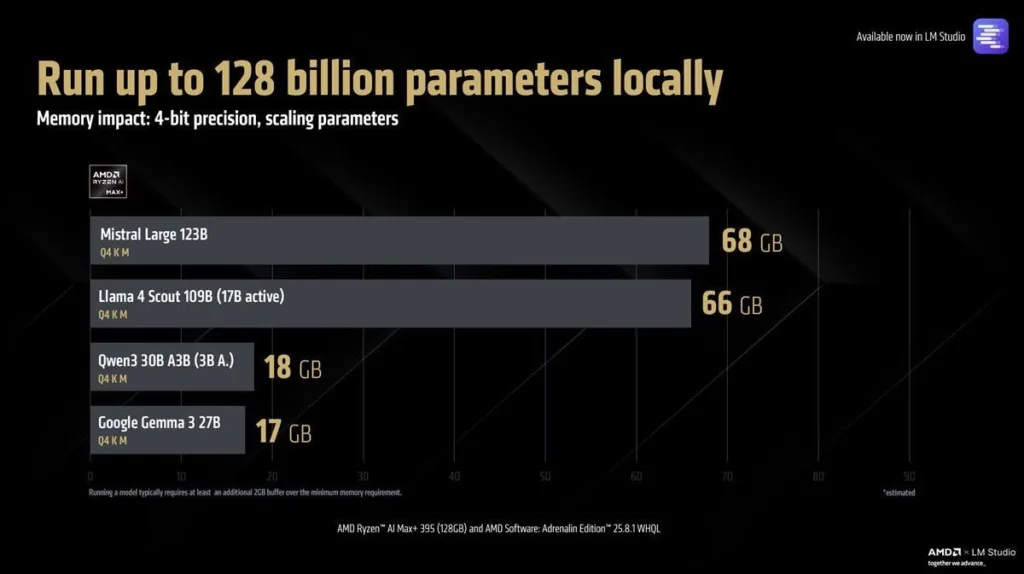
Ventajas y limitaciones
- Ventajas: baja latencia, mayor privacidad y poder de IA en local sin depender de nube.
- Limitaciones: requiere hardware específico (mínimo 16 GB RAM). Además, modelos MoE demandan cargar todos los parámetros aunque no se ejecuten todos.
Conclusión: un nuevo estándar RAM móvil de OpenAI
- OpenAI impulsa la ejecución de IA avanzada en móviles con el lanzamiento del gpt‑oss‑20b.
- Este modelo claramente eleva el listón en hardware móvil: 16 GB se convierte en la nueva base para ejecutar IA local de gran escala.
- Aunque el modelo 120b sigue reservado a hardware profesional, la democratización de la IA local ya empieza a materializarse.
Este anuncio marca un paso decisivo hacia el futuro de la IA en dispositivos personales.

